This week’s post is a reblog of a post by Daniel S. Katz, Sandra Gesing, Olivier Philippe, and Simon Hettrick on the URSSI blog at http://urssi.us/blog/2018/06/21/results-from-a-us-survey-about-research-software-engineers/, and reproduced here with the permission of Dan Katz.
First, some summary stats from the survey tweeted by Dan Katz:
- 90% write software that contributes to published research
- 82% don’t have hand-over plans for their important software
- 78% have trained others
- 75% have experience in demand in the labor market
——–
In 2016, the UK Software Sustainability Institute (SSI) ran a first survey of Research Software Engineers (RSEs): the people who write code in academia. This produced the first insight into the demographics, job satisfaction, and practices of RSEs. To support and broaden this work, the Institute planned to run the survey every year in the UK and an ever-expanding number of countries so that insight and comparison can be made across the globe. Ultimately, the SSI hopes that these results, the anonymized version of which are open licensed, will act as a valuable resource to understand and improve the working conditions for RSEs.
In 2017, led by Olivier Philippe and Simon Hettrick from the SSI, a set of such surveys were run across the the UK, Canada, Germany, the Netherlands, South Africa, and the US. One or more people from each non-UK country “translated” the questions so that they made sense in the local language and culture. The UK team ran the surveys, with the collaborators from the other countries—Scott Henwood (Canada), Stephan Janosch and Martin Hammitzsch (Germany), Ben van Werkhoven and Tom Bakker (Netherlands), Anelda van der Walt (South Africa), and Daniel S. Katz and Sandra Gesing (USA)—helping to publicize the survey in their countries. When the surveys were complete, the UK team analyzed the data, and published it for all countries. Building the survey and doing the analysis were done on GitHuband the output data has been published on Zenodo.
This blog post is a short summary of the results for this first USA survey, based on the Jupyter notebook that analyses the data. Given that Dan and Sandra are part of the team conceptualizing a US Research Software Sustainability Institute (URSSI), and because this survey brings up issues that URSSI might address, we are publishing this summary on the URSSI blog.
Possibly the most important insight provided by the survey is that 90% of respondents have written software that has directly contributed to published research. This confirms the central role of RSEs (and anyone who performs this role regardless of their job title) in the generation of research results.
In 2016, the UK Software Sustainability Institute (SSI) ran a first survey of Research Software Engineers (RSEs): the people who write code in academia. This produced the first insight into the demographics, job satisfaction, and practices of RSEs. To support and broaden this work, the Institute planned to run the survey every year in the UK and an ever-expanding number of countries so that insight and comparison can be made across the globe. Ultimately, the SSI hopes that these results, the anonymized version of which are open licensed, will act as a valuable resource to understand and improve the working conditions for RSEs.
In 2017, led by Olivier Philippe and Simon Hettrick from the SSI, a set of such surveys were run across the the UK, Canada, Germany, the Netherlands, South Africa, and the US. One or more people from each non-UK country “translated” the questions so that they made sense in the local language and culture. The UK team ran the surveys, with the collaborators from the other countries—Scott Henwood (Canada), Stephan Janosch and Martin Hammitzsch (Germany), Ben van Werkhoven and Tom Bakker (Netherlands), Anelda van der Walt (South Africa), and Daniel S. Katz and Sandra Gesing (USA)—helping to publicize the survey in their countries. When the surveys were complete, the UK team analyzed the data, and published it for all countries. Building the survey and doing the analysis were done on GitHuband the output data has been published on Zenodo.
This blog post is a short summary of the results for this first USA survey, based on the Jupyter notebook that analyses the data. Given that Dan and Sandra are part of the team conceptualizing a US Research Software Sustainability Institute (URSSI), and because this survey brings up issues that URSSI might address, we are publishing this summary on the URSSI blog.
Possibly the most important insight provided by the survey is that 90% of respondents have written software that has directly contributed to published research. This confirms the central role of RSEs (and anyone who performs this role regardless of their job title) in the generation of research results.
Demographics
164 people completed the survey past the first page, and listed themselves as working in the USA. 115 selected male to represent their gender, while 19 selected female, 6 selected “prefer not say”, and 24 did not answer. 77% of those who provided an ethnic origin described themselves as white, 11% as Asian, 8% as Hispanic, Latino, or Spanish, 6% as other, and 2% as Black or African American. Of those who provided their age, 38% were between 25 and 34, 31% between 35 and 44, 20% between 45 and 54, and 9% between 55 and 64.
According to the 2010 US Census and the Bureau of Labor Statistics, the overall US population is about 50% male and 50% female, 72% white, 5% Asian, 16% Hispanic or Latino American, 6% other, and 13% Black or African American, and the demographics of those employed are roughly similar to those of the overall population. 40% of the labor force is people from ages 16 and 36, 33% from ages 37 and 52, and 25% from ages 53 to 71.
It is interesting to note that the gender imbalance reported here is shared across the other countries that ran RSE surveys. It ranged from a maximum of 92% male in South Africa to a minimum 63% male in the Netherlands. The reason for this require closer investigation, but it is likely to be caused by the gender imbalance in physics and computer science – the main subjects from which RSEs are drawn. It is clear that the RSE community must work to address this imbalance.
Of those who entered their salary, 3% reported less than $30,000, 7% from $30,000 to $50,000, 18% from $50,000 to $70,000, 20% from $70,000 to $90,000, 21% from $90,000 to $110,000, 11% from $110,000 to $130,000, 6% from $130,000 to $150,000, and 7% more than $150,000. 3% reported having a condition defined as a disability by the Americans with Disabilities Act (ADA). 60% of those who reported their highest degree reported a PhD, 25% a Masters, and 12% an undergraduate degree. The high proportion of RSEs reporting a PhD supports the assumption that RSEs understand not just software engineering but also research, and are therefore better placed to work with researchers. Respondents reported a wide variety of subjects for their highest degree, including 25% in computer science, 15% in biological sciences, 15% in physics and astronomy, 11% in engineering, 9% in chemistry, and 5% in mathematics.
Coding
163 respondents write code, and about 75% of them write code that is at least half for others to use. 61% of the respondents consider themselves professional software developers, and the average development experience of the respondents is 14 years. This implies that there are people with a relatively large amount of development experience who do not consider themselves professional software developers, perhaps because they see themselves as “researchers who write software” rather than software developers, or it may be that the lack of recognition for the contribution of RSEs leads them to undervalue their position. While all respondents said they spend time coding each month, they (on average) spend less time on research, then less on management, and the least on teaching. About education, it worths to mention that 78% of them provided training to other researchers in computational techniques. 52% conduct testing on their software, while 35% have users do testing, and 7% do no formal testing. Studies suggest that around 70% of research relies on software [DOI:10.5281/zenodo.1183562], and if almost a half of that software is untested, this is a huge risk to the reliability of research results.
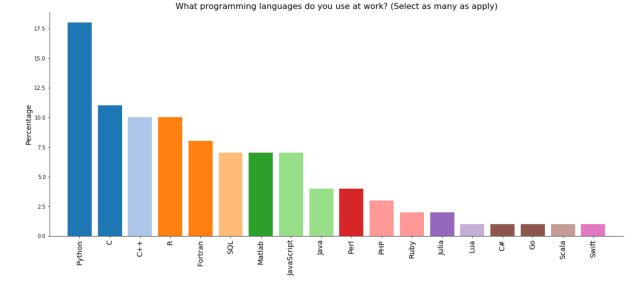
82% do not have a technical hand-over plan for their most important software project, and the bus factor for the same project is 1 for 39% of respondents, 2 for 36%, and 3 or more for the remaining 25%. 74% of respondents use Python, 45% C, 43% C++, 40% R, and 31% use Fortran.

Employment and Job Satisfaction
75% work for universities, 11% for national labs, and 5% for industry. 96% work full-time. 42% are employed permanently as long as funding is available, 40% permanently on institutional core funds, and 15% fixed term. They have been at their current institution a mean of 6.4 years. 51% have their largest project funded by grants, 29% by the institution, 8% by industry, and 6% are volunteering their time on their largest project. The survey also asked the reason for the respondents accepting their current position, with answers that included the desire to advance research, the desire to work in a research environment, freedom to choose own working practices, long-term prospects for continued employment, learning new skills, the opportunity to develop software, flexible working hours, the ability to work across disciplines, salary, and the opportunity for career advancement. The results are summarized below, and they may explain why RSEs choose to work in academia rather than industry, where they can command significantly higher salaries: ultimately, they care about making a contribution to research and are willing to take a lower salary for that opportunity.

The mean response on job satisfaction was about 8 of 10 (where 0 is not at all satisfied and 10 is completely satisfied). Respondents’ jobs generally satisfied them, and they were not eager to move to another job, at least at the same level of compensation, as shown below:

While the data is difficult to summarize, about 45% of respondents felt it would not be difficult for them to get an equivalent job in a different organization while 25% felt it would be difficult, about 75% said they could think of a number of organizations that would probably offer them a job while about 10% couldn’t, and about 75% said that their experience is in demand in the labor market while about 10% didn’t. They also generally positively scored the recognition they receive from their management, and reported that they find enjoyment in and are enthusiastic about their job. While only a minority felt it was likely they would gain a promotion within their current group, a majority felt that they had many options, and that their current position as an integral part of their career plan.
Collaboration
52% of respondents work with different researchers and regularly change who they work with, possible as a generalist across fields or within a field, while 48% consistently work with the same researcher(s), being embedded in a single research group. 43% work in an RSE group at their institution, while 57% do not. The mean number of projects a respondents works on is just under four. 78% of respondents have trained others, and they do so a mean of about six times per year. There are no courses that train a person to conduct the work of an RSE, so the only way to acquire these skills is to through self-learning or working with another RSE.
Publications
90% of respondents have written software that has contributed to published research. 80% are generally named as co-authors in this case, 71% are acknowledged in the paper, and 29% are a main author of the paper. 65% have presented their software at a conference. 81% have released open source software, and 48% always release their code as open source. 32% have used a DOI to identify their software.
Continuing discussion
There are a number of questions that this survey brings up, and we would be happy to have them discussed in the URSSI discussion forum, in part to see what the potentially role of URSSI could be in addressing the questions. In addition to the questions we have suggested below, which we have created as topics in the discussion forum, we also encourage readers to start discussions around other questions.
- Should there be a US RSE organization, similar to the UK one? (more discussion here)
- How do the salaries for RSEs compare with those of other researchers? How could this be studied? If there is a difference, could URSSI do anything to address it? (more discussion here)
- Given that 42% of responding RSEs are employed permanently as long as funding is available, 40% are employed permanently on institutional core funds, and 15% are employed fixed term, is this reasonable? How does it compare to other researchers and other research staff? Is there a role for URSSI to play here? (more discussion here)
- What can be done to address the gender imbalance in the RSE community? (more discussion here)
- How can we teach RSE skills to people who wish to pursue a career in research software engineering? (more discussion here)


 The poster is based on the Open Access paper “
The poster is based on the Open Access paper “
